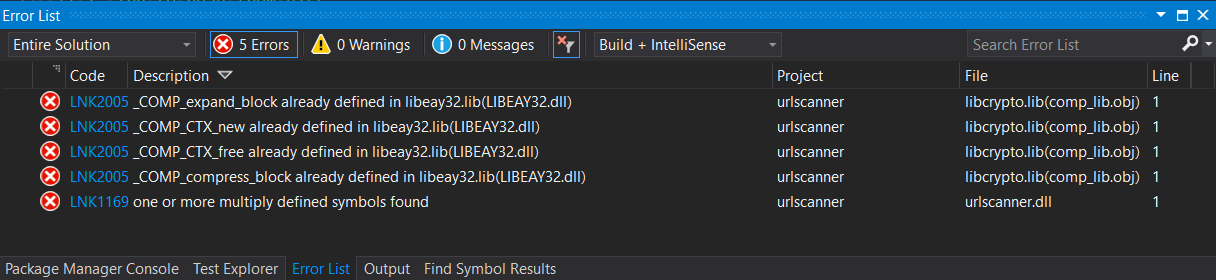
Trying to get table indexes information in SQL Server 2012 I identified a strange situation within a specific method that I was using so long but it was not acting as expected in one situation.
Usually, I got the right information about indexes but in one situation I encounter a strange behavior. It’s about having a clustered index into a scenario.
I have a table that contains two indexes referenced to some fields: IndexField_1 and IndexField_3 mapped over int, NULL fields. When IndexField_1 is Non-Unique, Non-Clustered and IndexField_3 is Clustered index I get the right information.
But if the index IndexField_1 is Clustered and the IndexField_3 is Non-Unique, Non-Clustered I get no information about IndexField_1 index (eg. szIdxName and szIdxColName are “” and their length is -1 that means SQL_NULL_DATA). Within while loop, with the next iteration I get correct information about the second index IndexField_3.