openSSL vs. vcpkg – some strange experiences
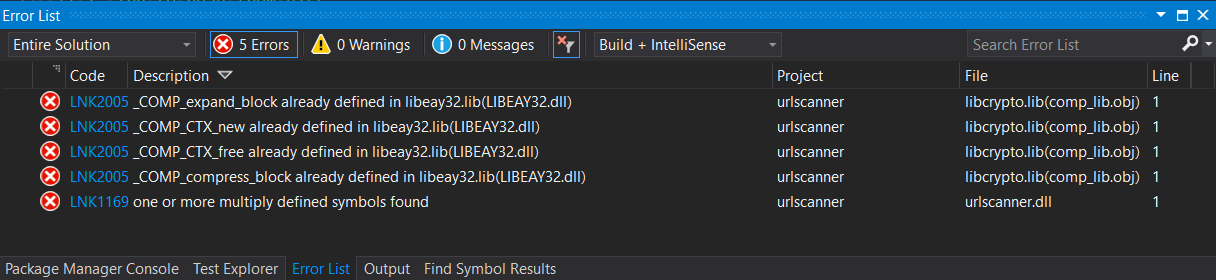
Some unexpected experiences caused by the fact the vcpkg C++ package manager is still based on OpenSSL 1.0.2.
Some unexpected experiences caused by the fact the vcpkg C++ package manager is still based on OpenSSL 1.0.2.

I am pleased to announce my first cross-platform and open source project, the Process Status Analysis tool, available on GitHub.
The Process Status Analysis (psa) is a command line tool that offer some Operating System processes analysis features:
– Get all processes loaded in memory information
– Get process only used memory
– Print processes tree
– Top most “expensive” processes
– Redirect output to a file
I wrote this document after a challenging experience I had recently within an Adobe Acrobat/Reader plugin creation. Even if the Adobe’s SDK it’s nicely documented… Read More »Experiences with Adobe Acrobat/Reader Plug-ins