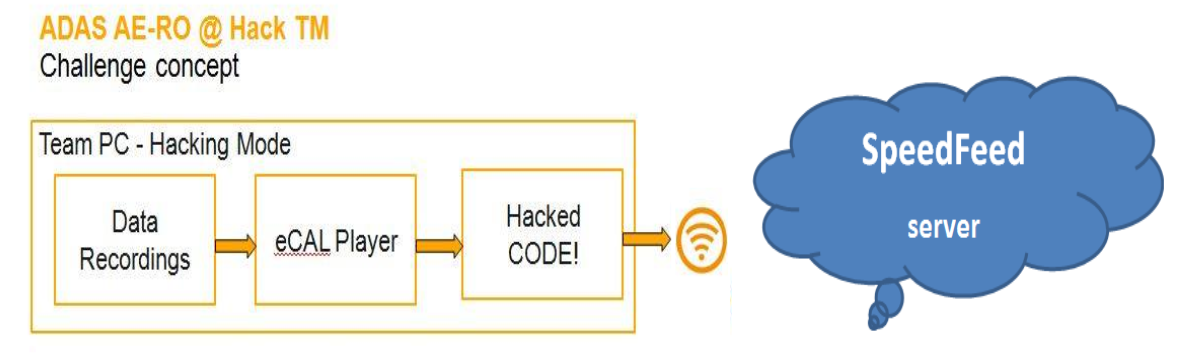
The First Hackathon Experience #HackTM2016
Some inside from my first hackathon experience, the #HackTM2016 from Timisoara.
Some inside from my first hackathon experience, the #HackTM2016 from Timisoara.
This is a story of how I got over a blocking situation within some Windows 10 OS installs on my Samsung laptop.
This is the story of my first experiences with Raspberry PI 2 card computer. Back in March, I bought a new toy, a Raspberry PI 2.… Read More »apt-get and the static IP challenges within Raspbian OS
As you most probably know, this website uses WordPress. Last Saturday, trying to access the site admin area I was faced with an error generated… Read More »Some experiences with the last world-wide WordPress brute force attack
If you’re behind of a proxy server and the IP address has changed (or proxy it’s a new node in your network topology) then probably when you’re trying to update your binaries then you’ll get a list of errors.
[bash]
W: Failed to fetch http://security.ubuntu.com/ubuntu/dists/oneiric-security/multiverse/i18n/Translation-en_US Unable to connect to 192.168.120.240:3128:
W: Failed to fetch http://security.ubuntu.com/ubuntu/dists/oneiric-security/multiverse/i18n/Translation-en Unable to connect to 192.168.120.240:3128:
[/bash]
This happens because you’re unable to connect to Ubuntu mirrors. In order to fix this issue you have to edit apt.conf file settings.
[bash]
root@my-server:~# vi /etc/apt/apt.conf
Acquire::http::Proxy “http://192.168.230.99:3128”;
[/bash]
Called by the compiler when you have more than one page of local variables in your function.
_chkstk Routine is a helper routine for the C compiler. For x86 compilers, _chkstk Routine is called when the local variables exceed 4K bytes; for x64 compilers it is 8K.
That’s all that you get from _chkstk()’s msdn web page. Nothing more…

My currently default bowser is Google Chrome. I use it more then 90% browsing time. I like it because is launching so fast, is a secure broswer, respects major W3C standards and has an interesting application architecture. Each tab is an independent process and if appears some troubles in one tab, you can stop that process only, without loosing other Chrome’s tabs data.
Unfortunately, two weeks ago, watching few slides presentations over slideshare.net I was shocked by a Windows message on my laptop: “Your computer is low on memory. Save your files and close these programs: Google Chrome.”
Preliminary remarks
Application path (Sun Solaris Unix OS): /myApp/myapp111a/
Database location: /myApp/db/test_db
Usually, our workstations have Windows OS and we need to connect to Solaris Unix OS on SSH. That’s why we are using Putty application.
User: root
Password: xxxxxxxxxx
[…]